Every developer will, or have at some point, encountered this dreadful experience… the intimidating tech interview. In this series of posts I will cover some of the typical topics that arise in tech interviews, starting with searching and sorting algorithms most commonly applied to List based collections.
“Before anything else, preparation is they key to success.”— Alexander Graham Bell
Arrays
Arrays are probably the most common data structure, found in the majority languages used today. Generally 0 based indexes are used (the first element is at index 0).
Mainly 2 types exist:
Linear arrays which are static in size, usually defined during construction.
Dynamic arrays that contain extra space reserved for new elements, once it is full elements are copied into a larger array.
Arrays are excellent for looking up values by index, which is performed in constant time, $O(1)$, but bad for inserting and deleting elements. The cause for this is that elements need to be copied to make space for new elements or to close the gap caused by deletion. Insert and delete operations are performed in linear time $O(n)$
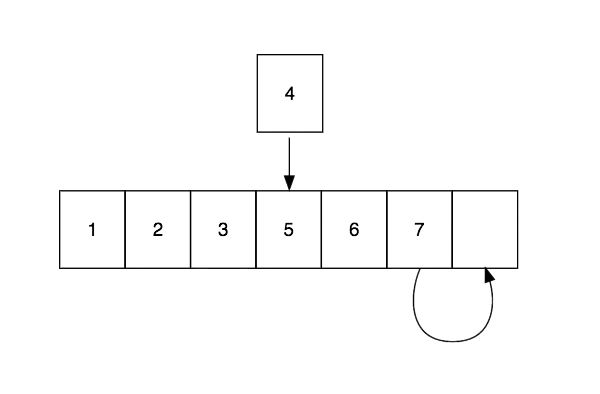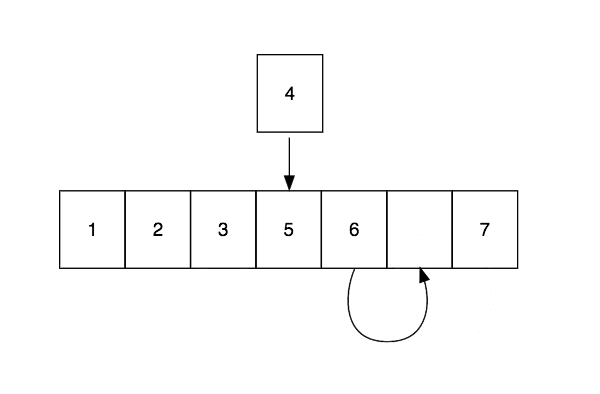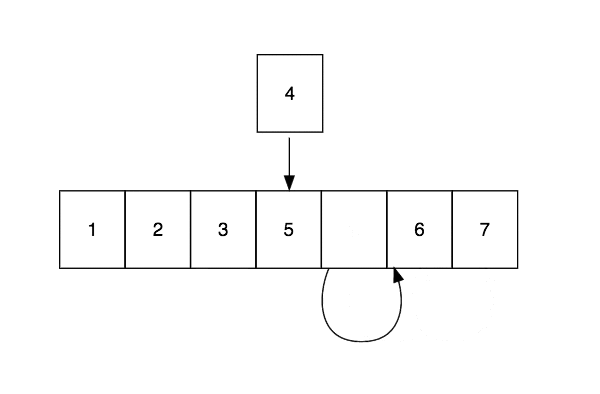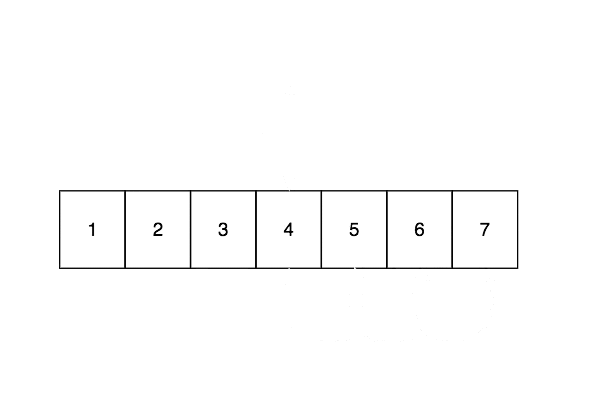
Linked Lists
The basic building block of a Linked List is a node. A node contains a single value and a reference to the next node in the list. This dynamic data structure is optimised for insert and delete operations, which happen in $O(1)$
In contrast to Arrays, index based lookup & searching performance is poor, $O(n)$, since potentially the entire list will have to be traversed to find an element.
In a Doubly linked list, each node has a reference to the next and previous node. Circularly linked lists have their first and last nodes connected.

Stacks
A Stack provides quick ( $O(1)$ ) access to the head (first) element and is an example of a LIFO (Last In First Out) data structure. Elements are pushed onto the stack and popped off. A Stack can be implemented as a Linked List where the push operation inserts at the head and pop removes from the head.
Queues
A Queue is an example of a FIFO (First In First Out) data structure. The oldest and newest elements are called the Head and Tail respectively. Elements are Enqueued to the Tail of the queue and Dequeued from the Head. A Queue can be implemented using a Linked List, by keeping track of both the Head and Tail.
A Deque is a double ended Queue, enqueueing or dequeueing can happen on either end.
Queues have the same performance characteristics as Linked Lists, $O(1)$ for enqueue/dequeue but $O(n)$ for searching.
Searching & Sorting
Binary Search
Given an array of sorted numbers, and x (the number being searched for). Recursively look at the element in the middle of the array, repeat on the left side if x is smaller than the middle element or on the right if its bigger. For even number arrays you will have to choose whether to use the lower or upper number as the “middle”.
Example:
Given [1,2,3,4,5,6,7,8] and x = 10:
- Split the array, using the lower element as the middle for even sized arrays.
- Iteration 1: Middle = 4, 10 > 4, search the upper half [5,6,7,8].
- Iteration 2: Middle = 6, 10 > 6, search the upper half [7,8].
- Iteration 3: Middle = 7, 10 > 7, search [8].
- Iteration 4: 10 > 8, thus the array does not contain the target value x.
“For interviews, memorize the time efficiency of well know algorithms and learn to spot them”— code monkey
Calculating Complexity
When faced with an unknown algorithm, one trick is to use a table that tracks the number of iterations for each increase in the input size of the array. Below is a table that applies this technique to the binary search algorithm. Upon closer inspection it roughly looks like the number of iterations increase when the input size doubles:
$$\begin{array}{|c|c|} \hline n & 0 & 1 & 2 & 3 & 4 & 5 & 6 & 7 & 8 \\ \hline \text{iterations} & 0 & 1 & 2 & 2 & 3 & 3 & 3 & 3 & 4 \\ \hline \end{array}$$
$$\begin{align} n & \approx 2^\text{iterations - 1} \\ \text{iterations}& \approx log_2 (n) + 1\\ complexity & \approx O(log_2(n)+1) \\ & \approx O(log(n))\\ \end{align}$$
Simple python implementation (iterative):
Bubble sort
Bubble sort is the simplest of sorting algorithms and probably the one most developers will naturally come up with when they are first faced with the problem. The algorithm basically compares two adjacent elements and swaps them if the order is wrong. This process is repeated until no more swaps happen. Worst case scenario is when the input is in reverse order, that will result in every element being compared to every other element, $O(n^2)$. On the up side, it is an in place sorting algorithm that requires no extra space, $O(1)$.
Merge sort
Merge sort is an example of a Divide and Conquer algorithm. Recursively split the input array until you have arrays with $\le 2$ elements. Then merge 2 adjacent arrays by comparing the first elements, since each array is already sorted. Rinse and Repeat.
The complexity of the algorithm would roughly be $\text{no_comparisons} \times \text{no_iterations}$. The number of comparisons (worst case) is approximately 1 less than the input size. To calculate the number of iterations, the same trick used in Binary Search can be applied, namely map the number of iterations against the input size and try to spot a pattern.
$$ \begin{array}{|c|c|} \hline & 2^0 & 2^1 & & 2^2 & & & & 2^3 & \\ \hline \hline n & 1 & 2 & 3 & 4 & 5 & 6 & 7 & 8 & 9 \\ \hline iterations & 0 & 1 & 2 & 2 & 3 & 3 & 3 & 3 & 4 \\ \hline \end{array}$$
$$\begin{align} n& \approx 2^\text{iterations} \\ \text{iterations}& \approx log(n) \\ \text{comparisons}& \approx n \\ complexity& \approx O(\text{comparisons} \times \text{iterations}) \\ & \approx O(n \ log(n)) \\ \end{align}$$
Quick sort
Pick a pivot element at random (convention picks the last number), then move all the numbers less than the pivot to the left of the pivot and all numbers larger to the right. Keep doing this recursively for the lower numbers to the left of the pivot and the higher numbers to the right of the pivot.
Quick Sort is an in place sorting algorithm with a space complexity of $(O(1))$.
Worst case time complexity is when the pivot does not split the array roughly in half. If the pivot belongs at the end, then you will end up comparing it to all the other numbers without swapping. This is compounded if the 2nd number has the same scenario. Thus worst case complexity for Quick Sort is the same as Bubble Sort, $O(n^2)$. Average case is $O(n\ log(n))$. Quick Sort does offer some opportunity for optimisation, for example the splits can run in parallel.
In part 2 of this series I will look at hash functions & maps.